TOPN vs INDEX
Rewriting a DAX query that uses TOPN with INDEX to investigate ease of use and performance characteristics
Now I have DAX Syntax Highlighting working on my blog I wanted to revisit some exploration I did with window function when they first came out. This was based on some DAX written by Phil Seamark that Counts numbers of last known state. The measure counts, for each day, the most recent State for each TestID.
Semantic Model¶
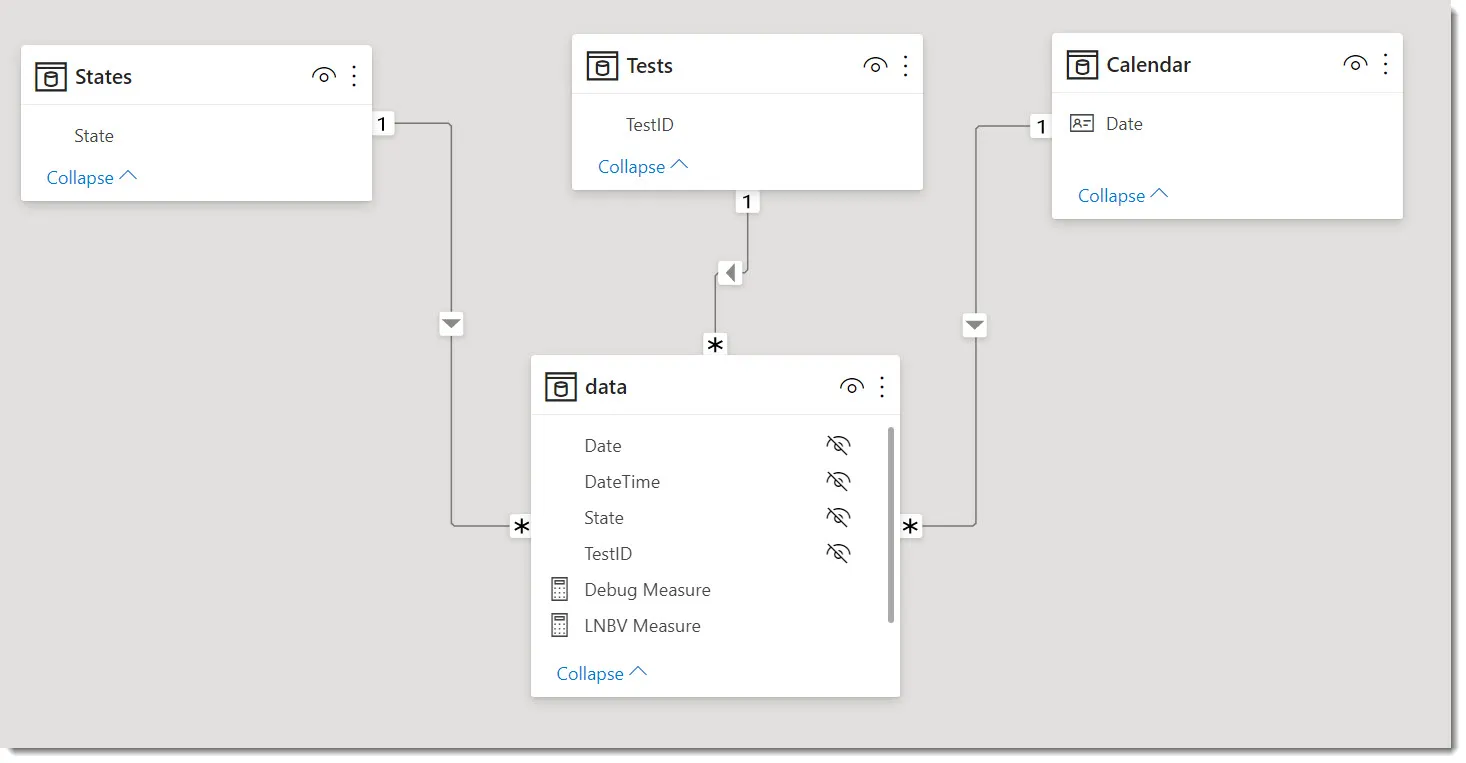
Measure¶
Phil's blog pre-dated window functions so I thought it would be interesting to refactor this measure, swapping TOPN with INDEX and observe the differences.
// Using TOPN
VAR currentState = SELECTEDVALUE(States[State])
VAR currentDate = SELECTEDVALUE('Calendar'[Date])+1
RETURN
COUNTROWS(
FILTER(
ALL( data[TestID] ),
SELECTCOLUMNS(
TOPN(
1,
CALCULATETABLE(
FILTER(
'data',
[DateTime] < currentDate
)
,REMOVEFILTERS('Calendar'[Date])
,REMOVEFILTERS('States'[State])
),
'data'[DateTime],
DESC
),
"Last Value", [State]
)
= currentState
)
)
// Using INDEX
VAR currentState = SELECTEDVALUE(States[State])
VAR currentDate = SELECTEDVALUE('Calendar'[Date])+1
RETURN
COUNTROWS(
FILTER(
ALL( data[TestID] ),
SELECTCOLUMNS(
INDEX(
1,
CALCULATETABLE(
FILTER(
data,
data[DateTime] < currentDate
)
,REMOVEFILTERS( 'Calendar'[Date] )
,REMOVEFILTERS( 'States'[State] )
)
,ORDERBY( data[DateTime], DESC)
,
,MATCHBY( data[DateTime] )
),
"Last Value", [State]
)
= currentState
)
)
Measure Comparison¶
I ran both measures in DAX studio, with a cleared cache and Server Timing turned on.
EVALUATE
SUMMARIZECOLUMNS(
'Calendar'[Date],
'States'[State],
"Using_TOPN", [Using TopN]
"Using_INDEX", [Using INDEX]
)


Comparison¶
Both of these measures create the same Storage Engine (SE) queries.
-- 1
SELECT 'data'[TestID] FROM 'data';
-- 2
SELECT 'States'[State] FROM 'States';
-- 3
SELECT 'Calendar'[Date] FROM 'Calendar'
-- 4
SELECT
'data'[RowNumber],
'data'[DateTime],
'data'[TestID],
'data'[State]
FROM 'data';
The dataset is very small so we can ignore the actual performance timings. To test the difference in performance I extended the data to 20,000 rows.

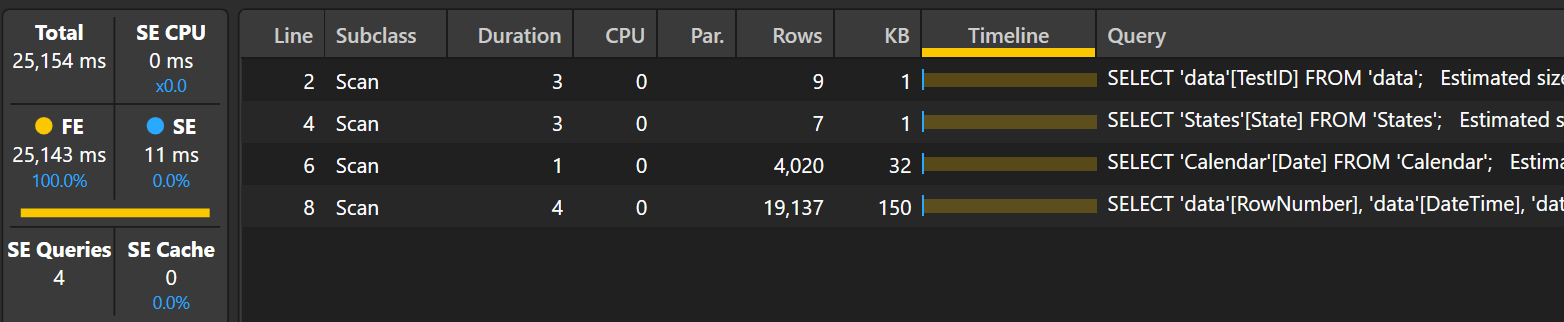
TOPN quickly performs it's SE queries, followed by a substantial period of Formula Engine (FE). Interestingly INDEX takes twice the time to execute.
If we look at the Query Plans, the Logical Query Plans are almost identical. But on the Physical Query Plans we see some differences. Both queries end up at the same point, at a CrossApply EqualTo '(Calendar'[Date]), ('States'[State]), ('data'[TestID]) on ('Calendar'[Date], 'States'[State], 'data'[TestID]), where the latter is the most recent State of the given TestID on a given Date. The main difference is INDEX joins ('Calendar'[Date], 'data'[TestID], 'data'[State]) with the ordered list of ('Calendar'[Date], 'data'[TestID], 'data'[RowNumber-2662979B-1795-4F74-8F37-6A1BA8059B61], 'data'[DateTime], 'data'[State]) to determine nth row.
Conclusion¶
While the semantics of TOPN and INDEX measures are similar, the underlying algorithm and therefore query plans differ, resulting in differences in query performance. If you want to return the nth item, INDEX can be a good solution. TOPN only works out for the first or last item. Another option would be to use RANK/RANX, but the measure might be less readable, and the performance would need to be quantified. When trying to develop or optimize a measure you should try to experiment with a few variations to check the characteristics of each before landing on a final design.